

Data Engineering Newsletter #21
Data Engineering News


1. Moving Data with Python and dlt: A Guide for Data Engineers
🚀 Are you efficiently moving data with Python and dlt?
Moving data is more than just transferring bits from A to B; it's a puzzle where every piece must fit perfectly. This guide walks you through dlt, an open-source Python library that simplifies data movement across APIs, databases, cloud storage, and filesystems. From setting up a pipeline to handling incremental loads, this article gives you the blueprint to build efficient and scalable data workflows.
https://www.datacamp.com/de/tutorial/python-dlt
2. Splicing Duck and Elephant DNA
What happens when you splice duck and elephant DNA?
Postgres is a powerhouse for transactions, but it struggles with analytics. This article by Jordan Tigani and Brett Griffin introduces pg-duckdb, an open-source extension that embeds DuckDB into Postgres, merging the best of both worlds. With blazing-fast analytical queries inside your favorite transactional database, this is a game-changer for developers and data engineers alike.
https://motherduck.com/blog/pg_duckdb-postgresql-extension-for-duckdb-motherduck/
3. Build a poor man’s data lake from scratch with DuckDB
Can you build a data lake on a budget with just DuckDB?
The explosion of data tools has made things more complex, but what if you could simplify everything with just DuckDB? In this article, Pete Hunt & Sandy Ryza explore how to build a lightweight, high-performance data lake from scratch using DuckDB, Dagster, and Parquet on S3.
https://dagster.io/blog/duckdb-data-lake
4. Build a high-performance quant research platform with Apache Iceberg
Can Apache Iceberg revolutionize quant research?
Data is everything in quantitative finance, but managing it is a bottleneck. The authors explore how Apache Iceberg optimizes query performance, reduces costs, and streamlines data management, accelerating strategy development while ensuring data integrity.
5. Accelerate queries on Apache Iceberg tables through AWS Glue auto compaction
Can AWS Glue auto-compaction make Apache Iceberg even faster?
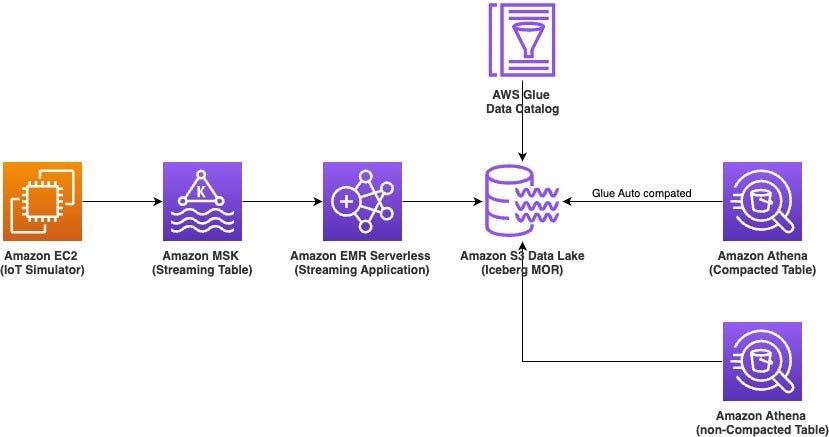
This article explores how AWS Glue’s automatic compaction for Apache Iceberg tables optimizes performance, reduces metadata overhead, and accelerates queries, especially for streaming data. The post dives into real-world benchmarks, showing how auto compaction can cut query times by over 50%, streamline storage, and improve efficiency in large-scale data lakes.
6. Why There’s Never Been a Better Time to Adopt Apache Iceberg as Your Data Lakehouse Table Format
Is now the best time to switch to Apache Iceberg for your data lakehouse?
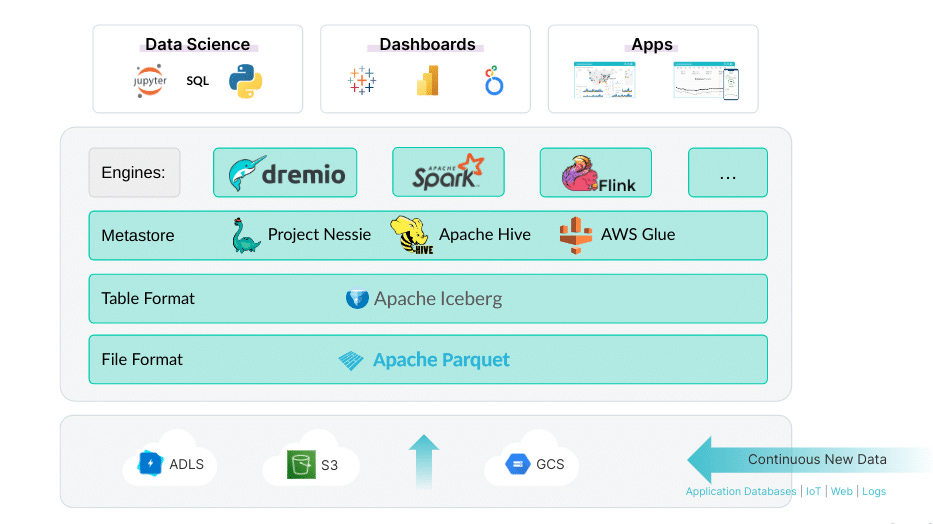
Apache Iceberg is not just another table format; it’s the foundation of a modern, scalable, and vendor-agnostic data lakehouse. With ACID transactions, time travel, schema evolution, and seamless compatibility with major analytics engines, Iceberg is revolutionizing how data is managed at scale.
All rights reserved Den Digital, India. I have provided links for informational purposes and do not suggest endorsement. All views expressed in this newsletter are my own and do not represent current, former, or future employer opinions.